
HTTP/2 Server Push可能存在的攻击方式
什么是 Server Push
Server Push是HTTP/2规范中引入的一种新技术,可以类比HTTP/1.1的keep-alive机制,允许客户端和服务端用同一个 TCP 连接发送/接收多个请求/响应,减少了昂贵的 TCP 建立连接和断开连接的过程,还有HTTP/1.x的Pipelining机制,允许客户端在收到响应之前继续发送幂等方法(GET 和 HEAD)的请求,提升在高延迟连接下页面的加载速度,而Server Push是为了提前推送响应。
使用 HTTP/1.x 协议时,由于连接不能完全被复用,许多站点为了减少连接数和请求数,会把样式表和脚本内联到 HTML 中。如果不考虑缓存,可以认为这是提前推送了样式表和脚本的响应。许多介绍 server push 的文章也以推送这些静态资源为例。
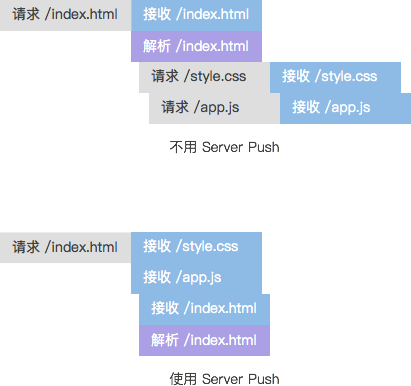
可以看到,使用 server push 后,两个静态资源文件随着 HTML 一同被推了回来。主要省去了两部分时间:一部分是接收和解析 HTML 的时间(不一定是接收和解析完整 HTML 的时间,浏览器很可能一发现引用了静态资源文件,就发起请求);另一部分是请求静态资源文件的时间。
Server Push 现阶段缺陷
- HTML 文件通常不大,而且样式表一般很靠前,浏览器发现这类静态资源的时间几乎可以忽略不计;
- HTTP/2 已经能够复用 TCP 连接了,请求不再像以前那样昂贵,请求的实际数据很小,发送请求的时间也几乎可以忽略不计;
- 国内的 CDN 普遍不支持 server push,这意味着,如果要推送静态资源,就必须耗费自己服务器的带宽,同时也享受不到 CDN 的各种好处了;
- 静态资源通常会被缓存很长时间,提前推送的话,在大多数情况下反而会浪费流量。
因此,我们推送的资源并不是静态资源,而是 API:
- 相比较静态资源文件,浏览器更难发现 API 请求,必须等到接收和解析完 JS 文件,执行到相关语句,浏览器才会发送请求;
- API 一般不缓存,即便缓存,缓存的时间也比静态资源短得多。
Server Push 过程
假设服务端接收到客户端对 HTML 文件的请求,决定用 server push 推送一个样式表文件。那么,服务端会构造一个请求,包括请求方法和请求头,填充到一个 PUSH_PROMISE 帧里发送给客户端,来告知客户端它已经代劳发了这个请求。客户端可以根据 PUSH_PROMISE 帧里提供的 Promised Stream Id 来读推过去的响应。
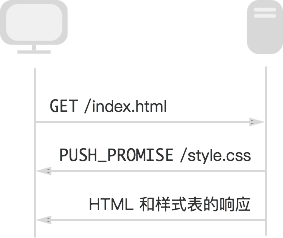
这里需要注意的是避免竞争。在上面的例子中,必须先发送 PUSH_PROMISE,再发送 HTML 的内容。这是因为 HTML 中存在对样式表文件的引用,一旦客户端发现了这个引用却还没收到 PUSH_PROMISE,它就会发起请求。这会引起 PUSH_PROMISE 和对样式表文件的请求之间的竞争,从而 server push 有一定的几率失败。
另一种竞争是不可避免的。如果客户端认为它不需要某个即将被推过来的资源(比如这个资源还在缓存的有效期内),那么它会 reset 掉相应的流。但是即便如此,服务端在收到 RST_STREAM 帧的时候,很有可能已经推了一部分数据了。这种服务端开始推送数据和 RST_STREAM 帧之间的竞争是难以避免的(这是 feature 而不是 BUG)。



